Fossil Data Platform Rewritten in Rust 🦀
My data engineering team at Fossil recently released some of Rust-based components of our Data Platform after faced performance and maintenance challenges of the old Python codebase. I would like to share the insights and lessons learned during the process of migrating Fossil's Data Platform from Python to Rust.
- The Need for Change
- Why Rust is chosen?
- The Drawbacks of Using Rust
- The plan
- The First Benchmark
- Going Production
- Spark and Rust
- Team involvement
- Well, what's next?
- The feature of Rust for Data Engineering
- Where to start?
The Need for Change
With the Fossil Data Platform handling approximately 1.2 billion records daily in near-real time, our existing Python codebase started showing signs of strain. We had been using Python for years and encountered issues such as duplicated code, deprecated components, hardcoded elements, and a lack of comprehensive reviews. This situation prompted a critical evaluation of our options:
- Continuing with Python: We contemplated rewriting the platform while sticking with Python. However, considering our data engineering requirements, we recognized the need for a language more suitable for the task.
- Rewrite into data-engineering-friendly language like Java or Scala, given their popularity in the data engineering domain.
- Exploring other compiled languages
After careful consideration, I decided to adopt Rust as the language of choice for rewriting our Data Platform. While Rust was relatively new at the time, it demonstrated significant potential, especially as a way to escape from the JVM ecosystem.
No one had experience with Rust at all. However, I viewed it as an opportunity for both the team and the project to grow and learn. There were many promising aspects, and even if I were to fail, my teammates and I would still learn valuable lessons.
Why Rust is chosen?
All programming languages cannot solve all problems on their own. We should choose a language based on its unique features, design choices, and how it can help us address challenges we faced in the past.
In the deliberation between Rust and Golang for our next Data Platform, we weighed the advantages of both languages while working with a sizable Python codebase and encountering difficulties. Here are the key reasons why Rust emerged as the preferred choice:
- Excellent tooling. No need to struggling with Python virtual environment, pip dependencies management,
PYTHONPATHor deployment anymore. Withcargo, a powerful package manager, these tasks become streamlined and simplified. Havingcargo fmt,cargo clippy, andcargo testRust's approach to testing all built into the language with well-established community standards means that it's that much easier. - Rust follows a strict approach, ensuring that even with suboptimal design, compiled code will function correctly, provided you have comprehensive test coverage. Even you don’t have a good design, your code will always works if it compiled.
- The compiler is your best friend. The error output is very detailed, a lot of contexts, it tells you what causes the error and where you can find the cause. In many cases, it even provides a fix for the error.
- Unique approach to memory management, which guarantees memory safety without the overhead of a garbage collector, resulting in a smaller memory footprint and predictable performance, critical factors in data-intensive applications like our Data Platform.
- You can learn some more at this post https://blog.duyet.net/2021/11/rust-data-engineering.html
The Drawbacks of Using Rust
Steep Learning Curve
Rust's advanced features and strict adherence to memory safety principles can result in a steep learning curve for developers.
You will say: Wtf is From, TryFrom, AsRef, Arc, Pin, Feature, …
To become proficient, you need to learn the complex language syntax, common idioms, and libraries. This could take weeks or even months of frequent practice. I started with some small projects like athena-rs, grant-rs, or glossary-rs at first, and keep learning by building micro project like that until now.
Development Speed
Languages like Python and Go make you feel productive from day one, but Rust slows down development speed due to the extra complexity of memory safety. While Rust crates like serde, polars, and ballista provide good support for data engineering, they might not offer the same level of maturity and feature completeness as more established languages. This may require additional effort to work around limitations or implement missing functionality.
Long Compile Times
Rust is known for having relatively longer compile times, especially for larger projects. Current full project compilations can take 30 minutes, which can slow down the development feedback loop. This longer compilation duration can make it more challenging to iterate quickly and test changes. However, there are techniques available to optimize Rust's compilation speed, such as those mentioned in resources like "Fast Rust Builds", “Stupidly effective ways to optimize Rust compile time” or "Delete Cargo Integration Tests."
The plan
My plan revolved around taking an exploratory approach to determine the feasibility and effectiveness of Rust for our Data Platform
- Initial Prototype: I took the initiative to delve into Rust and develop a first runnable prototype that would be evaluated against a predefined set of criteria. This prototype aimed to showcase Rust's capabilities and assess its potential in solving our existing problems.
- Evaluation and Team Involvement: Once I can proved with the team the initial prototype is promising, we intended to involve additional team members in the development process. Their expertise and perspectives would help validate the viability of Rust for our Data Platform.
- Become the mainstream: As the project gained momentum, our plan was to gradually transition the entire team to Rust. This shift would allow us to leverage the distinctive features and advantages of Rust effectively, enabling us to tackle the challenges we had faced.
The First Benchmark
My first version took three months to rewrite and has shown excellent performance even without optimization, the memory .clone() everywhere. I conducted some benchmarks including cargo bench and transforming the real data files as well.
After comparing the two components in the real environment, Rust processes messages faster and consumes more messages than Python.
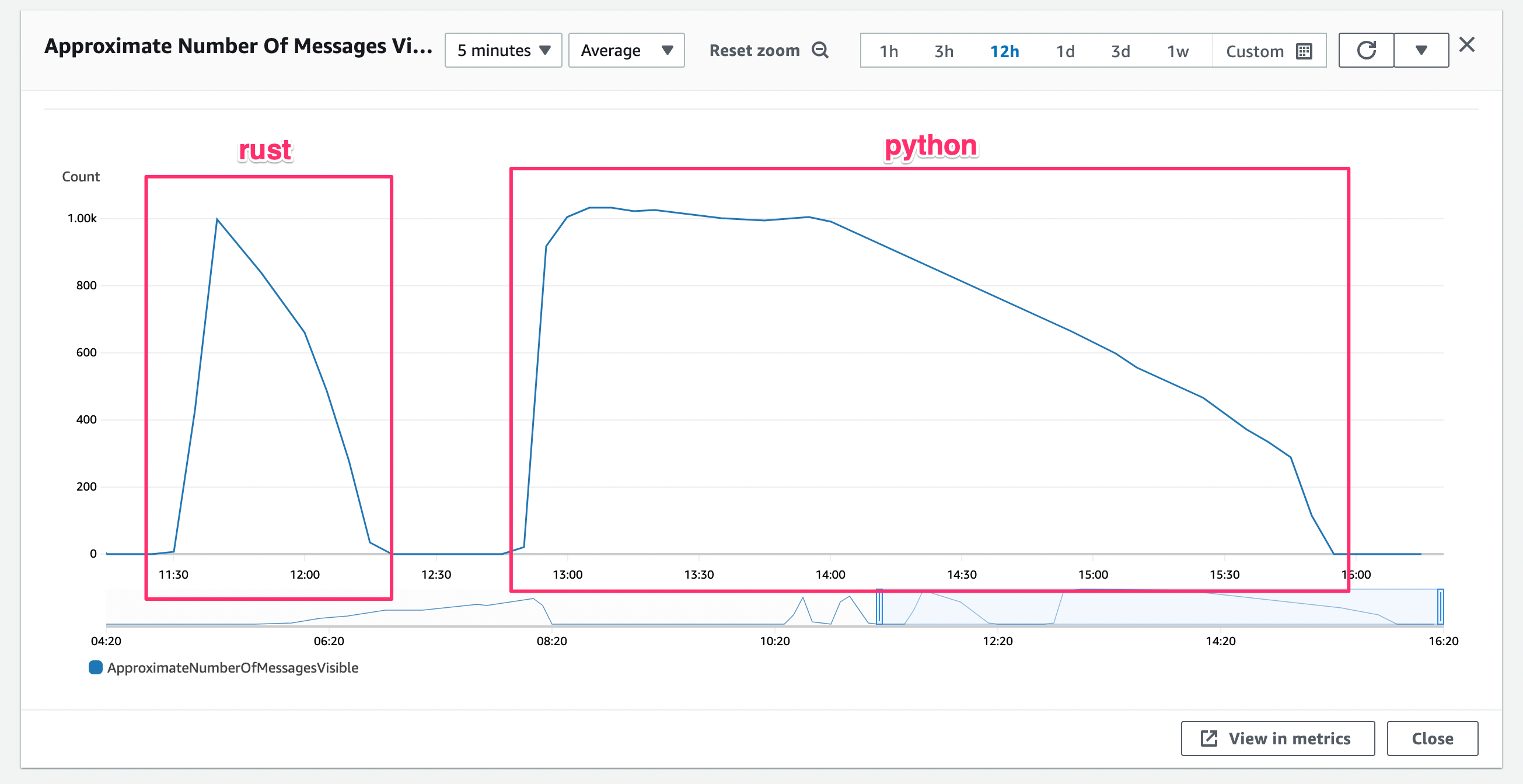
Despite the lack of fine-tuning and potential areas for optimization, Rust demonstrated its inherent efficiency and ability to handle our data processing requirements effectively:
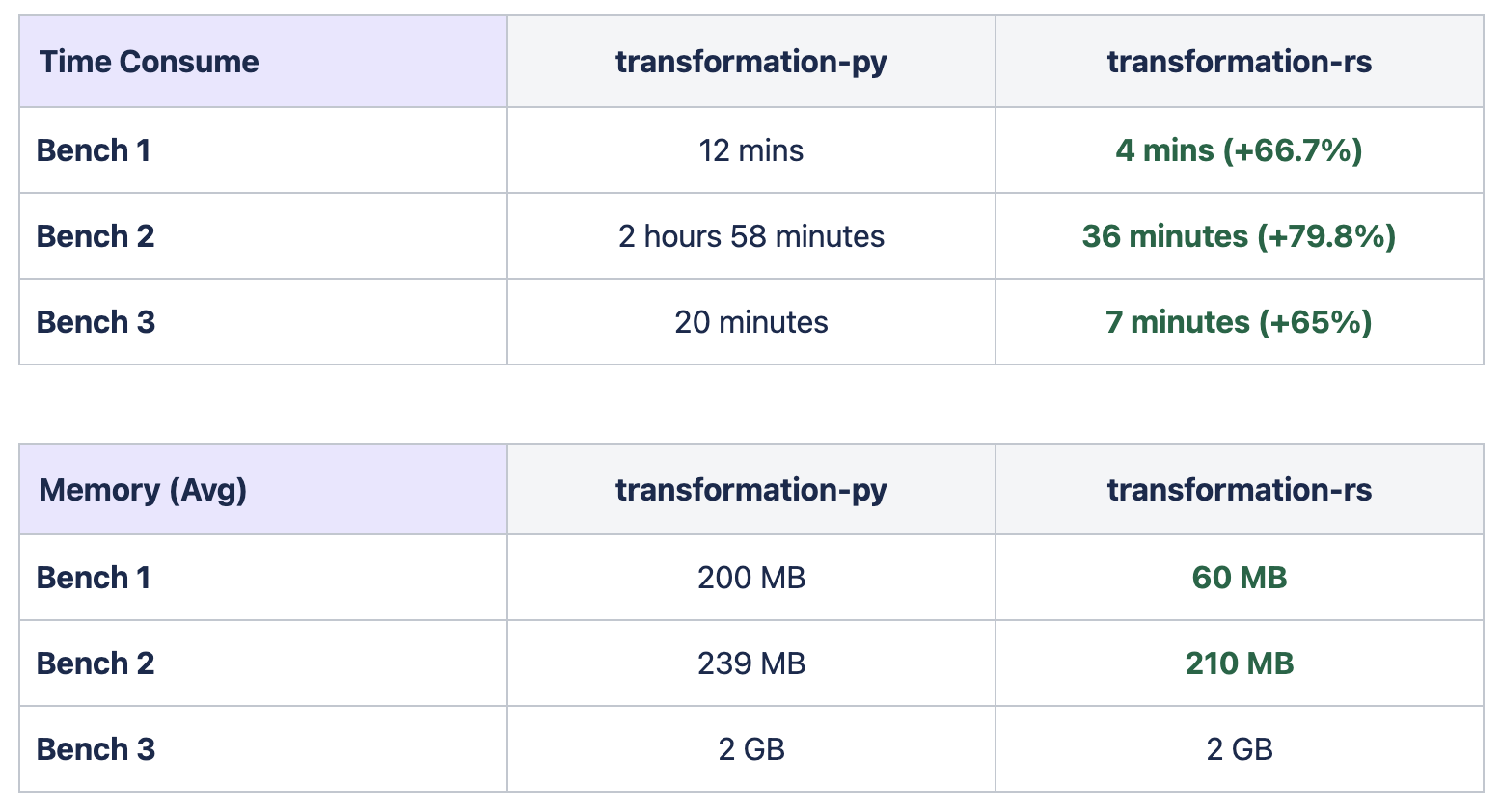
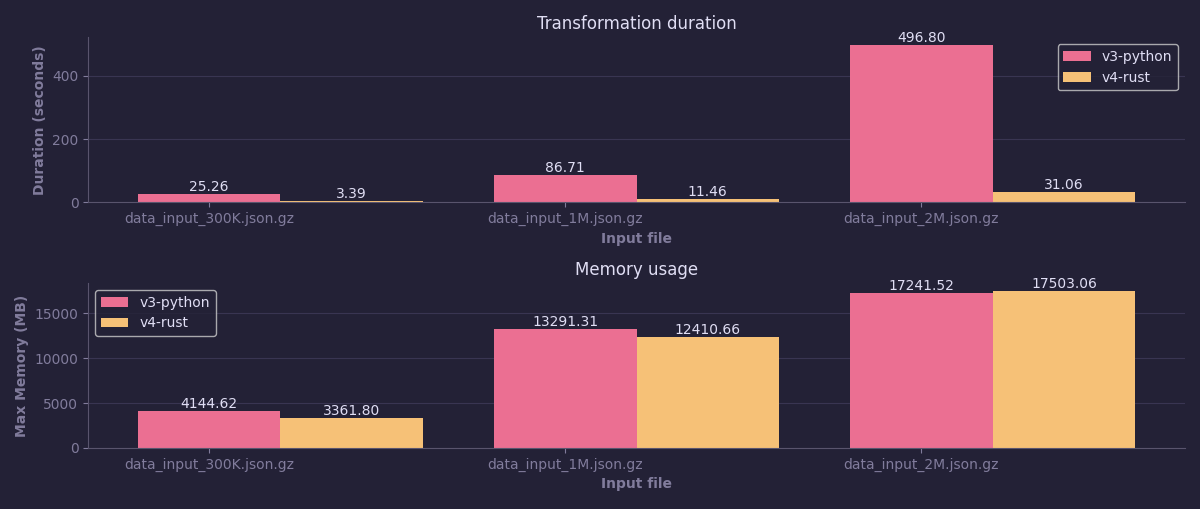
The image above displays the recent benchmark results by Hieu of Data Platform v3 (Python) vs v4 (Rust) in terms of processing time and memory usage. Rust outperformed Python by achieving a 490% faster processing time while maintaining the same memory usage. It's worth noting that Arrow was used as the data layout format during the benchmark. Based on this benchmark, the team started optimizing memory usage to further improve the performance of the Data Platform.
Moving forward, our focus shifted to further optimizing the code, eliminating unnecessary memory clones, and leveraging Rust's advanced features to unlock even greater efficiency.
The need to ensure backward compatibility with the previous Python-based inline transformation without disrupting the current configuration. I will need FFI to interact with Python (thanks to PyO3) which decreased the performance, but this trade-off is acceptable.
# example config.yaml
---
source_field: properties
target_field: config_value
transformations:
- name: custom_code
language: python
code: |
year = datetime.now().strftime("%Y")
return source_field.get("config_name").lower()
Going Production
For easier to understand, the platform should be configured as shown in the figure below. It runs on Kubernetes with KEDA for fully automated scaling. During peak periods or migration, it can scale up to 1000 pods using Python-based workers. Data collector was written in Node.js, now rewritten in Rust thanks to actix-web.
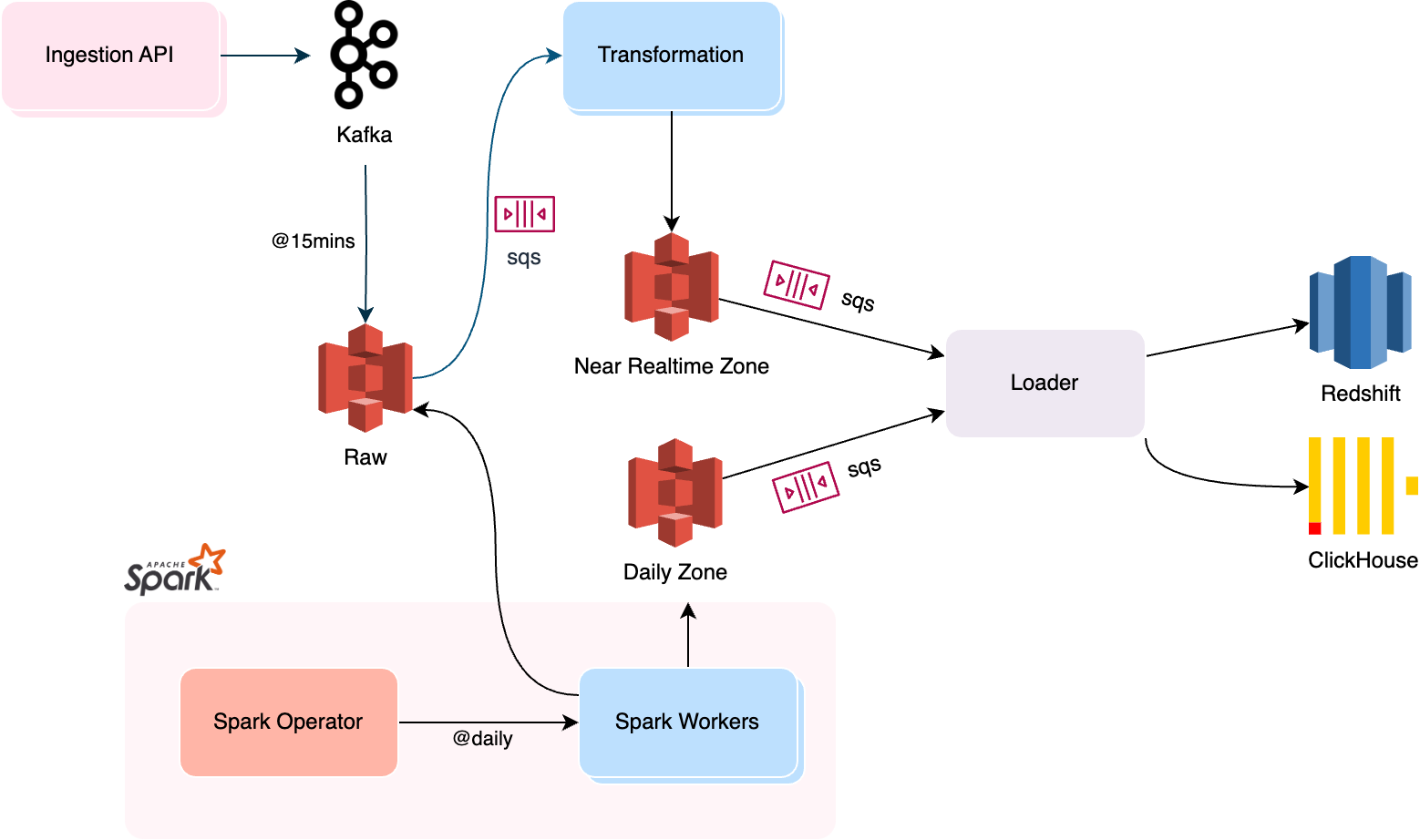
The initial plan involves replacing the mini-batch layer pods with transformation-rs. This reduces the number of pods to a range of 10-20, resulting in significant resource savings and improved performance.
| Transformation Worker | Python | Rust |
|---|---|---|
| Number of Pods (KEDA Scale) | 30-1000 pods | 10-50 pods |
The data collector API was initially developed using Node.js, but it has since been rewritten in Rust using the actix-web framework. This migration has resulted in several benefits, including reduced API call latency and improved resource utilization. By leveraging Rust's excellent performance and actix-web's powerful features, the data collector API can now handle requests more efficiently and with lower resource usage.
| Ingestion API | Node.js | Rust |
|---|---|---|
| Number of Pods (HPA Scale) | 5-30 pods | 1-5 pods |
Spark and Rust
I planned for doing POCs to explore ways to speed up the Spark cluster and integrated it with transformation-rs to use a single codebase for both. Our approach involved these options:
1. Create a Rusty Python Library
so that an UDF can use call to Rust directly, thanks to maturin.rs by helping us for building wheels for Python 3.7+ easily.
maturin will add the native extension as a module in your python folder. Example layout with pyo3 after maturin develop:
my-project
├── Cargo.toml
├── my_project
│ ├── __init__.py
│ ├── bar.py
│ └── _lib_name.cpython-36m-x86_64-linux-gnu.so
├── README.md
└── src
└── lib.rs
2. pyspark.RDD.pipe
This returns an RDD created by piping elements to a forked external process - our binary of transformation-rs.
Imagine we already have this binary running in a container for processing a file:
./transformation-rs --config config.toml -f dataset.json.gz
We can run it via Spark RDD like below:
sc.addFile("s3a://data-team/transformation-rs", false)
val ds = df.toJSON.rdd.pipe(SparkFiles.getRootDirectory + "transformation-rs").toDS
Checking out this great post to get more detail about this solution.
3. DataFusion
Replace Spark by Ballista: Distributed Scheduler for Apache Arrow DataFusion
Ballista is a distributed scheduler for Apache Arrow DataFusion, which offers a promising alternative to Spark. It provides an efficient and flexible way to process large datasets using distributed computing. By using Ballista, we can avoid the overhead and high costs associated with Spark and instead leverage the power of Apache Arrow DataFusion to process data efficiently.
Moreover, Ballista is designed to work well with Rust, which is known for its excellent performance and multi-core processing capabilities. This makes it an ideal choice for companies that want to process large datasets quickly and efficiently without the high costs associated with Spark.
While Ballista is still a relatively new technology, it shows great promise and is worth considering as an alternative to Spark. As more companies adopt Ballista and contribute to its development, we can expect to see even more improvements in its performance and capabilities.
4. You Don't Always Need Spark
While Spark is considered an excellent tool for processing very large datasets, we realized that we don't always have such large datasets to work with. Instead of running Spark workers on Kubernetes nodes with r6i.12xlarge (48 cores - 384 GiB) spot instances, which resulted in significant overhead and high costs.
We decided to experiment with just running Rust on these huge machines that would allow us to leverage the excellent performance of multiple core processing. By doing so, we hoped to see how Rust could perform on these powerful machines and whether it could be a viable alternative to Spark.
Team involvement
The decision to adopt Rust for our Data Platform has resulted in the entire team actively engaging with the language. The rest of the team is starting to learn and build with Rust. Hieu, Uyen, Khanh, Hung and Duong are starting to build or rewrite more key components of the Data Platform include the data ingestion API, data transformation workers, athena-rs (AWS Athena Schema Management), grant-rs (Manage Redshift/Postgres privileges in GitOps style), the Kafka configurations management, ...
https://rust-tieng-viet.github.io is one of the documents I could provide for the team at first.
However, there have been some changes, and the migration is progressing slowly due to other priorities.

Data Team 2022
Data Team 2023
Well, what's next?
We need to have continued our efforts to optimize and refine its performance. Furthermore, we are exploring opportunities to leverage the Rust-based Data Platform alongside Apache Spark for batch processing. Investigating the integration possibilities between the Rust-based platform and Apache Spark opens up new avenues for expanding our data engineering capabilities.
In parallel, we are actively working on ensuring backward compatibility with our previous Python-based Data Platform. This involves rigorous testing of the new Rust-based components with the existing configuration files and datasets.
After all, Hieu is leading the rewrite effort based on his experience from the first version and is implementing best practices. He plans to create partially open-source components that are backward compatible with Python, refactor the configuration, use Polars and DuckDB, enable parallel processing on the Tokio runtime, and carefully benchmark resource consumption. Hieu may provide detailed information and lessons learned at a later time through a highlighting article.
The feature of Rust for Data Engineering
Despite being the most loved language for seven consecutive years, Rust may still be considered relatively less popular in certain domains. However, I believe that Rust holds tremendous potential, especially for Data Engineering, and can emerge as a new trend in the field.
More and more data-sensitive and data pipelines application and framework in Rust nowaday. Let me tell you a few names:
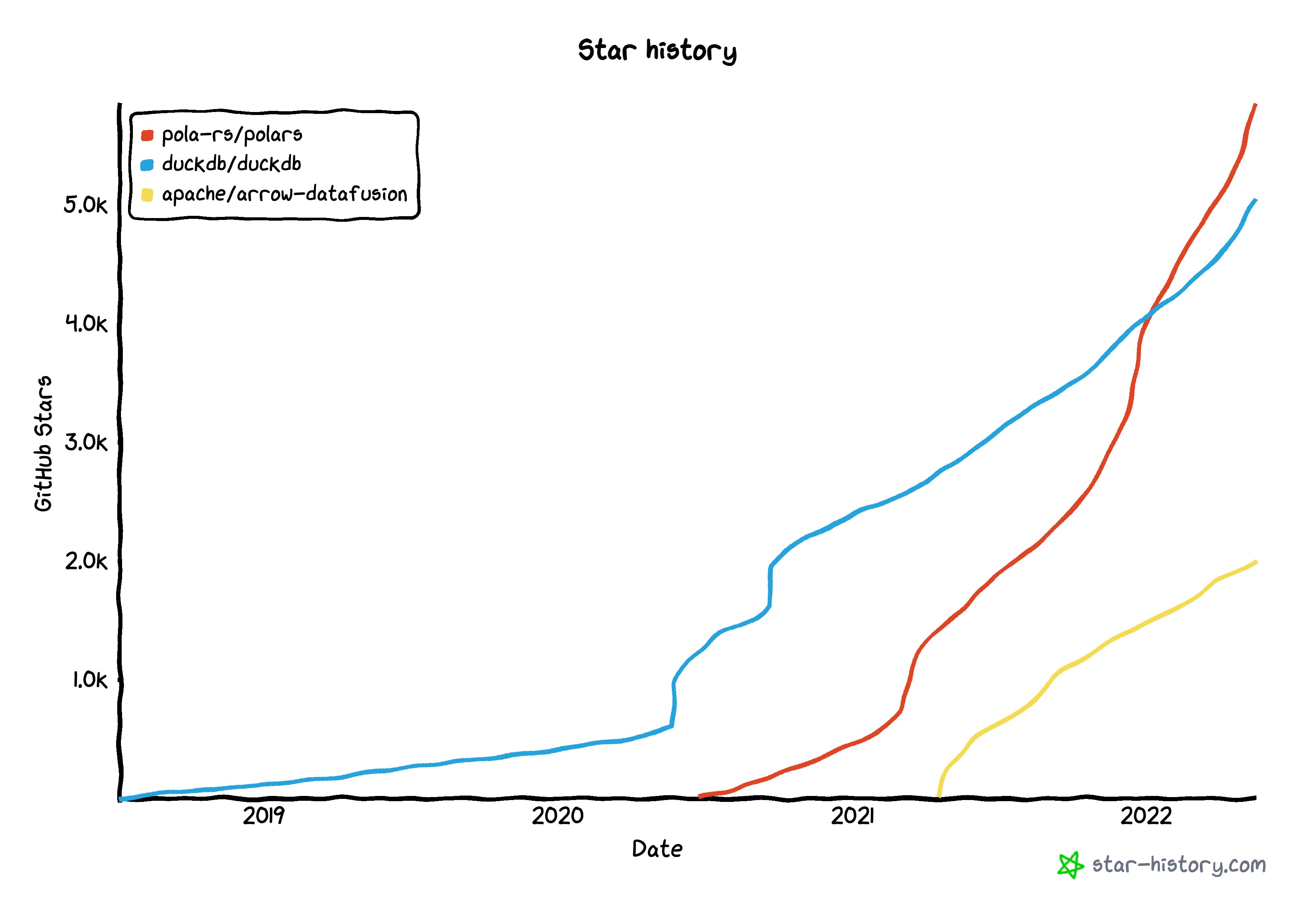
- apache/arrow-datafusion: Apache Arrow DataFusion SQL Query Engine
- TimelyDataflow/timely-dataflow: A modular implementation of timely dataflow in Rust
- vectordotdev/vector: A high-performance observability data pipeline
- pola-rs/polars: Fast multi-threaded, hybrid-out-of-core DataFrame library in Rust | Python | Node.js
- tokio-rs/tokio: A runtime for asynchronous applications provides I/O, networking, scheduling, timers, ...
- launchbadge/sqlx: 🧰 The Rust SQL Toolkit. An async, pure Rust SQL crate featuring compile-time checked queries without a DSL. Supports PostgreSQL, MySQL, SQLite, and MSSQL.
I have discussed the future with my team, and I bet and considered the possibility of Rust becoming the new trend in Data Engineering. We could be proud to have been one of the first teams to use Rust in building a Data Platform. However, even though Rust might become the standard when the platform is stable, it may still be difficult to hire new Rust developers, especially in Vietnam.
We chose Rust for developing many of our applications due to its high level of security for concurrent processing, as well as its focus on correctness and performance. Rust's compiler is an excellent tool for identifying bugs, but ultimately, it is important to measure the running code and identify bottlenecks in order to solve them.
References
- Will Rust Take over Data Engineering? 🦀
- Rust is for Big Data (#rust2018) - Andy Grove
- Rust và Data Engineering? 🤔
Where to start?
If you're considering diving into Rust for your own projects or migrating an existing codebase, I highly recommend starting with the Rust By Example book.
In addition, there are other valuable resources available to aid your learning and exploration of Rust. Here are a couple of links you may find helpful:
- Rust 101
- Learning Rust · Rust Programming Language Tutorials
- Introduction - Rust By Example
- The Rust Programming Language - The Rust Programming Language
- Introduction - Rust Design Patterns
- What is rustdoc? - The rustdoc book
- Introduction - The Rust Performance Book
- GitHub - Dhghomon/easy_rust: Rust explained using easy English
- Developing the Library’s Functionality with Test Driven Development - The Rust Programming Language
- Introduction - Rust Tiếng Việt
Series: Rust Data Engineering
Tại sao Rust là lựa chọn cho Data Engineering? Khám phá 7 lý do chính từ performance, memory safety, đến WebAssembly và hệ sinh thái data tools như Apache Arrow, DataFusion, và Polars. Bài viết chi tiết về ưu nhược điểm, learning curve, và tương lai của Rust trong lĩnh vực Data Engineering và Big Data processing.
This blog post will provide an overview of the data engineering tools available in Rust, their advantages and benefits, as well as a discussion on why Rust is a great choice for data engineering.
If you're interested in data engineering with Rust, you might want to check out Polars, a Rust DataFrame library with Pandas-like API.
My data engineering team at Fossil recently released some of Rust-based components of our Data Platform after faced performance and maintenance challenges of the old Python codebase. I would like to share the insights and lessons learned during the process of migrating Fossil's Data Platform from Python to Rust.