Topic Modeling: Tìm chủ đề cho tập văn bản bài viết
Note: This post is over 10 years old. The information may be outdated.
Một công ty A hoạt động trong lĩnh vực nghiên cứu thị trường đã tiến hành thu thập dữ liệu từ các trang báo điện tử Việt Nam để khảo sát xem thị hiếu của người dân về các chủ đề xã hội và đời sống như thế nào. Từ đó hỗ trợ cho các công ty bán hàng làm chiến lược marketing hiệu quả hơn. Dữ liệu được lấy về, lưu trên một cơ sở dữ liệu dưới định dạng file văn bản (.txt) mà chưa qua bất kỳ khâu xử lý nào. Do trong quá trình lấy dữ liệu, các kỹ thuật viên của công ty A đã sơ suất quên ghi nhớ chủ đề cho từng bài viết khi được tải về. Những gì công ty A hiện có là một thư mục chứa hơn 28,000 file văn bản (text), mỗi file văn bản là nội dung một bài viết trên một trang báo nào đó.
Câu hỏi: Với số lượng bài viết lớn như vậy (hơn 28,000 bài viết), bạn hãy tìm cách nào đó để nhóm các bài viết theo những chủ đề khác nhau. Bạn hãy đề xuất một phương pháp để có thể đặt tên cho từng chủ đề một cách hợp lý nhất. Kết quả công ty A mong đợi sẽ là một file dạng csv gồm 2 cột: cột 1 là tên bài báo, cột 2 là tên chủ đề tương ứng.
Download file dữ liệu 28,000 bài viết (link dự phòng).
Với lượng dữ liệu lớn như vậy, có 2 mục tiêu cần thực hiện:
- Nhóm các bài viết thành các chủ đề khác nhau
- Đặt tên chủ đề cho từng nhóm bài viết ấy.
Việc nhóm các văn bản thành các chủ đề khác nhau có thể sử dụng các thuật toán phân cụm như K-means, khai phá chủ đề LDA(Latent Dirichlet Allocation), ... Nhưng với LDA và cả K-means đều yêu cầu phải biết trước giá trị k - số cụm để phân chia.
Số cụm của đề bài không thể xác định chính xác. Quan sát dữ liệu, ta thấy được đa số các bài báo được lấy từ các trang tin lớn như VnExpress, Tuổi trẻ Online.
1. Phân tích về tên chủ đề bài viết trên báo điện tử
Phân tích một chút về danh mục chủ đề trên các trang báo này. Các mục tại VnExpress được phân thành từng mục chính, mỗi mục chính lại có các chuyên mục nhỏ.
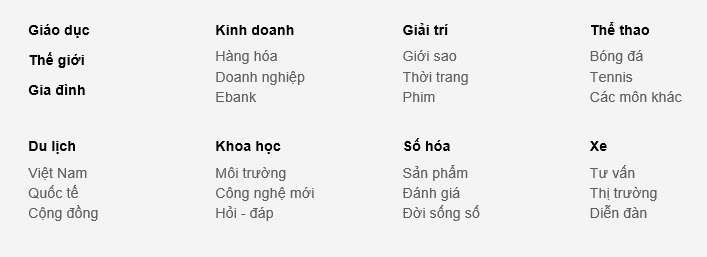
- Một số trang báo có các chuyên mục riêng: như mục Video (http://video.vnexpress.net), iOne (http://ione.vnexpress.net), ... là một mục nhỏ của VnExpress, nhưng lại có các chủ đề con cùng tên với tất cả các mục lớn của VnExpress.
- Khi thu thập bài viết từ nhiều nguồn, sẽ có trường hợp các bài viết trùng nhau (hoặc gần giống nhau), nhưng 2 báo lại có cách đặt tên chủ đề khác nhau.
- Một số trang tin tổng hợp (Zing.vn, Báo mới, ...) sẽ tổng hợp các tin từ các trang chính thống, và sẽ sắp xếp các bài viết vào các mục tương đương.
2. Phân tích dữ liệu thô
Dữ liệu thu được ở dạng text, mỗi file là một bài viết. Mỗi bài viết đều bị nhiễu (do thu thập dư các liên kết bài viết liên quan, các bài xem nhiều nhất, ...).
Dữ liệu cũng thu thập các bài ở dạng bài viết ảnh (chỉ thu thập được Caption của ảnh), hoặc bài viết Video (thu thập được số giây của video, ...).

Các dữ liệu này khá nhiễu, khó rút trích đặc trưng, cần phải trải qua trá trình tiền xử lý để xử lý các bài viết này.
3. Phương pháp thực hiện
3.1. Đề xuất phương pháp
Do sự khó khăn trong dữ liệu, và không xác định được số chủ đề của bài viết, cách đặt tên chủ đề, ... có nhiều phương pháp khác nhau để tiến hành nhóm các bài viết. Ta thống nhất sẽ chỉ chia các bài viết thành các chủ đề chính (không chia thành các chủ đề phân cấp nhỏ hơn). Tổng quát lại chúng ta sẽ có các cách sau để tiến hành nhóm các bài viết cùng chủ đề lại với nhau:
- Sử dụng thuật toán DBSCAN (Density-based spatial clustering of applications with noise): đây là thuật toán được đề xuất để phát hiện các cụm trong tập dữ liệu (chấp nhận dữ liệu nhiễu), với DBSCAN ta không cần biết trước số cụm. Nhược điểm của DBSCAN là độ phức tạp cao, chạy chậm.
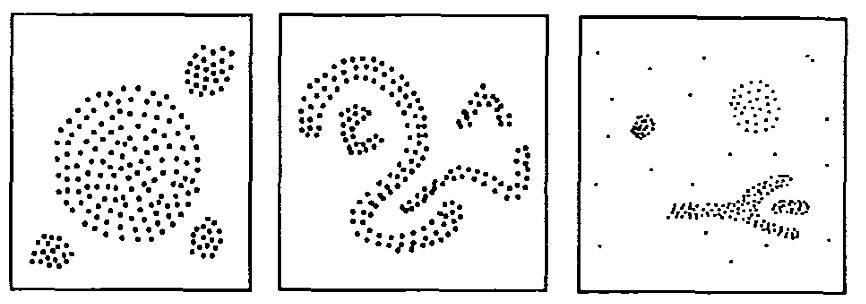
- Sử dụng thuật toán K-means: K-means sẽ phân cụm dữ liệu bài viết vào số cụm k xác định, số cụm có thể ước lượng từ các phân tích tên chủ đề ở trên. Công ty A thu thập dữ liệu từ các trang báo thuộc chủ đề xã hội và đời sống, tổng hợp lại ta sẽ có các chủ đề: Thời sự, Thế giới, Kinh doanh, Giải trí, Thể thao, Pháp luật, Giáo dục, Sức khỏe, Gia đình, Du lịch, Khoa học, Số hóa, Xe, Cộng đồng và mục khác. Số cụm ước lượng sẽ từ 13 ~ 15 cụm. Nếu các bài viết ở mục "Khác" chênh lệch lớn thì tiến hành điều chỉnh tham số k cho phù hợp.
- Sử dụng kỹ thuật phân lớp văn bản: kỹ thuật này có thể tốn thời gian nhưng hiệu quả và giải quyết được cả vấn đề gom nhóm và đặt tên chủ đề. Tiến hành thu thập rút trích lại một số bài viết từ tất cả các chủ đề trên báo điện tử, dữ liệu này thu thập sẽ bao gồm bài viết và nhãn (chủ đề) của bài viết đó. Sử dụng các phương pháp/công cụ thống kê hoặc máy học (Machine Learning) để tiến hành tạo ra mô hình, sử dụng mô hình để phân lớp cho 28.000 văn bản của công ty A.
Đặt tên chủ đề: Với phương pháp 1 và 2, việc làm sau khi phân cụm được các bài viết là tìm cách đặt trên cho các chủ đề này. Từ mỗi nhóm bài viết, ta có thể tiến hành rút trích từ khóa đặc trưng sử dụng mô hình túi từ, tính tần số, chọn ra các từ khóa đặc trưng. Từ các từ khóa đặc trưng này có ta thể suy luận ra được chủ đề, bằng phương pháp thủ công hoặc tự động. Để có các kết quả chính xác thì trong tập bài viết các từ stopwords, các ký hiệu đặc biệt, ... phải được lọc bỏ.

3.2. Thực nghiệm
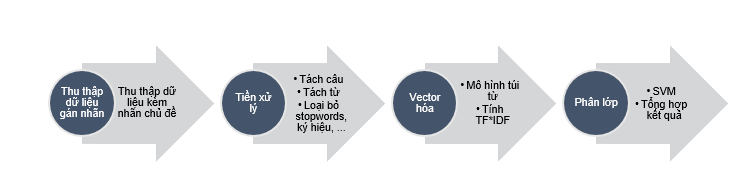
Trong giới hạn, mình không thể thực nghiệm hết được tất cả các phương pháp đã nêu, mà chỉ chọn một phương pháp truyền thống: sử dụng phương pháp thu thập lại và phân lớp chủ đề sử dụng SVM. Phương pháp gồm 4 bước cơ bản:
- Bước 1: Thu thập, rút trích Tiến hành thu thập, rút trích lại một số bài viết từ VnExpress.net và các chủ đề tương ứng đi kèm cho mỗi bài viết. Các chủ đề này sẽ là các chủ đề chuẩn cho 28.000 bài viết của công ty A.
- Bước 2: Tiền xử lý dữ liệu Tập văn bản (bao gồm thu thập được và dữ liệu thô có sẵn) sẽ được xử lý tách câu, tách từ, loại bỏ các dấu câu và các stopword. Sau bước này, mỗi văn bản sẽ là tập hợp của các từ đã được sàng lọc trong văn bản đó. Quá trình tách câu tách từ trong tiếng Việt được sử dụng công cụ vnTokenizer với độ chính xác được tác giả công bố 96% - 98%. Stopwords sẽ được xóa bỏ khỏi kết quả bằng cách sử dụng bộ từ điển stopwords tiếng Việt.
- Bước 3: Vector hóa văn bản Tập từ thu được từ bước tiền xử lý đang ở dạng không cấu trúc, do đó để xử lý phân lớp bằng các phương pháp máy học cần vector hóa chúng. Mô hình túi từ được áp dụng, theo mô hình này, dữ liệu văn bản không có cấu trúc (độ dài khác nhau) được biểu diễn thành dạng vector tần số xuất hiện của từ trong văn bản. Từ tần số của từ, vector của từng văn bản sẽ được tính bằng công thức TF*IDF (tham khảo).
Đây là công thức giúp đánh giá mức độ quan trọng của một từ đối với văn bản trong bối cảnh của tập ngữ liệu.
- TF (term frequency) là tần số xuất hiện của một từ trong một văn bản.
- IDF (inverse document frequency) là tần số nghịch của 1 từ trong tập ngữ liệu.
Kết quả của bước này là vector phân bố xác suất của tập từ biểu diễn chủ đề của từng văn bản. Các từ có tần số TF*IDF dưới 1 ngưỡng quy định sẽ bị lọc bỏ. Việc lọc này nhằm lựa ra những từ đủ tính chất đặc trưng cho chủ đề, loại bỏ những từ quá hiếm xuất hiện hoặc xuất hiện quá phổ biến.
- Bước 4: Phân lớp văn bản Tiến hành phân lớp sử dụng phương pháp học máy SVM. Tập văn bản đầu vào sau khi trải qua các bước xử lý sẽ được đại diện bằng tập các vector Chúng sẽ là đầu vào của giải thuật SVM truyền thống. SVM là thuật toán phân lớp nhị phân, do đó ta phải tổ chức sử dụng các kết hợp các mô hình One-vs-All hoặc All-vs-All Classification Sau quá trình phân lớp sẽ cho ta kết quả gãn nhãn chủ đề cho từng văn bản dựa trên văn bản đã thu thập được.
Có thể tổng quá quá trình thực hiện như sau
Tổng kết
Qua quá trình xử lý, ta được tập kết quả của 28,000 văn bản cùng với chủ đề. Với lượng dữ liệu lớn, mô hình xử lý đơn lẻ truyền thống không thể phân tích nhanh chóng và có hiệu quả. Có thể kết hợp thêm kỹ thuật phân tán hóa dữ liệu và song song các tác vụ để nâng cao tốc độ thực thi, cụ thể có thể sử dụng mô hình MapReduce của các framework Apache Hadoop hoặc Apache Spark